使用 Azure 的计算机视觉服务,开发人员可以访问用于处理图像并返回信息的高级算法。
主要包含如下高级算法:
标记视觉特性Tag visual features
检测对象Detect objects
图像分类Categorize an image
描述图像Describe an image
检测人脸Detect faces
检测图像类型Detect image types
检测特定领域的内容Detect domain-specific content
检测颜色方案Detect the color scheme
生成缩略图Generate a thumbnail
获取感兴趣区域Get the area of interest
从图像中提取文本Extract text from images
管理图像中的内容Moderate content in images
要使用Computer Vision,图像质量必须满足如下要求:
- 图像必须以 JPEG、PNG、GIF 或 BMP 格式显示
- 图像的文件大小必须不到 4 兆字节 (MB)
- 图像的尺寸必须大于 50 x 50 像素
- 对于 OCR,图像的尺寸必须介于 50 x 50 和 4200 x 4200 像素之间
若要分析图像,可以上传图像,也可以指定图像URL。
图像处理算法可以通过多种不同的方式分析内容,具体取决于你感兴趣的视觉功能。 例如,计算机视觉可以确定图像是否包含成人内容或不雅内容,或者查找图像中的所有人脸。
可以在应用程序中使用计算机视觉,方法是:使用本机SDK,或者直接调用 REST API。 SDK中,支持最全的是C# ,部分功能包含Java,NodeJS,Python,Go SDK。
实战视频案例Computer Vision :
B站 https://www.bilibili.com/video/av79419998/
或在本站观看视频:
下面分别举几个例子介绍计算机视觉API的功能:
图像标记-Tags
计算机视觉在上千个可识别对象、生物、风景和操作的基础上返回标记。 当标记内容不明确或者不属常识时,API 响应会提供“提示”来澄清标记在已知场景中的含义。 标记不按分类来组织,且不存在继承层次结构。 内容标记集合在一起,形成图像“说明”的基础。该“说明”以人类可读语言显示,采用完整句子的格式。 请注意,图像说明目前只能使用英语。
上传图像或指定图像 URL 后,计算机视觉算法在对象、生物和图像中标识的操作的基础上输出标记。 标记不限于主体(例如前景中的人),还包括场景(户内或户外)、家具、工具、植物、动物、配件、小器具等。

"tags": [
{
"name": "grass",
"confidence": 0.9999995231628418
},
{
"name": "outdoor",
"confidence": 0.99992108345031738
},
{
"name": "house",
"confidence": 0.99685388803482056
}]对象检测-Detect common objects in images
对象检测类似于标记,但是 API 返回找到的每个对象的边框坐标(以像素为单位)。 例如,如果图像包含狗、猫和人,检测操作将列出这些对象及其在图像中的坐标。

"objects":[
{
"rectangle":{
"x":730,
"y":66,
"w":135,
"h":85
},
"object":"kitchen appliance",
"confidence":0.501
},
{
"rectangle":{
"x":523,
"y":377,
"w":185,
"h":46
},
图像进行分类-Categorize images by subject matter
计算机视觉还返回图像中检测到的基于分类的类别。 不同于标记,类别是在父/子继承层次结构中组织的,并且数量更少(86 个,与数千个标记截然相反)。 所有类别名称均采用英语。 它可以单独完成分类,也可以与新的标记模型共同完成。

"faces": [
{
"age": 23,
"gender": "Female",
"faceRectangle": {
"top": 45,
"left": 194,
"width": 44,
"height": 44
}
}
]
已支持的分类列表:
https://docs.azure.cn/zh-cn/cognitive-services/computer-vision/category-taxonomy
除了上述内容,还支持手写体识别,表单识别等等,具体请参见官网:
https://docs.azure.cn/zh-cn/cognitive-services/computer-vision/concept-detecting-image-types
接下来,我们做一个案例,对如下图像进行检测,图像位置:
https://upload.wikimedia.org/wikipedia/commons/3/3c/Shaki_waterfall.jpg

本案例步骤:
- 在Azure创建Computer Vison API;
- 使用Azure提供的 Online API 测试工具;
- 使用Postman进行测试;
本案例完整内容,参照本文开始视频。
可使用如下地址进行在线测试:
https://dev.cognitive.azure.cn/docs/services/56f91f2d778daf23d8ec6739/operations/56f91f2e778daf14a499e1fa/console
其中必填项如下图所示:
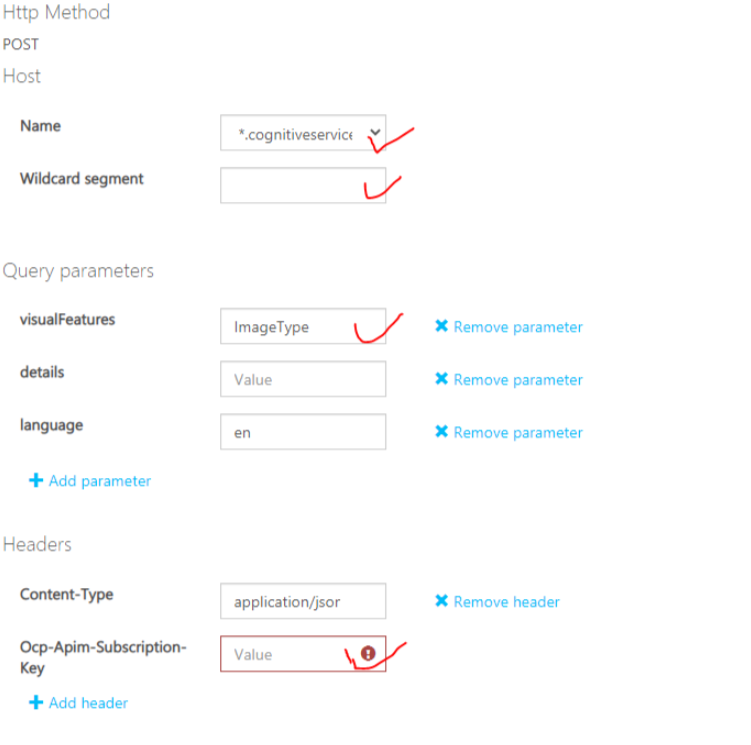
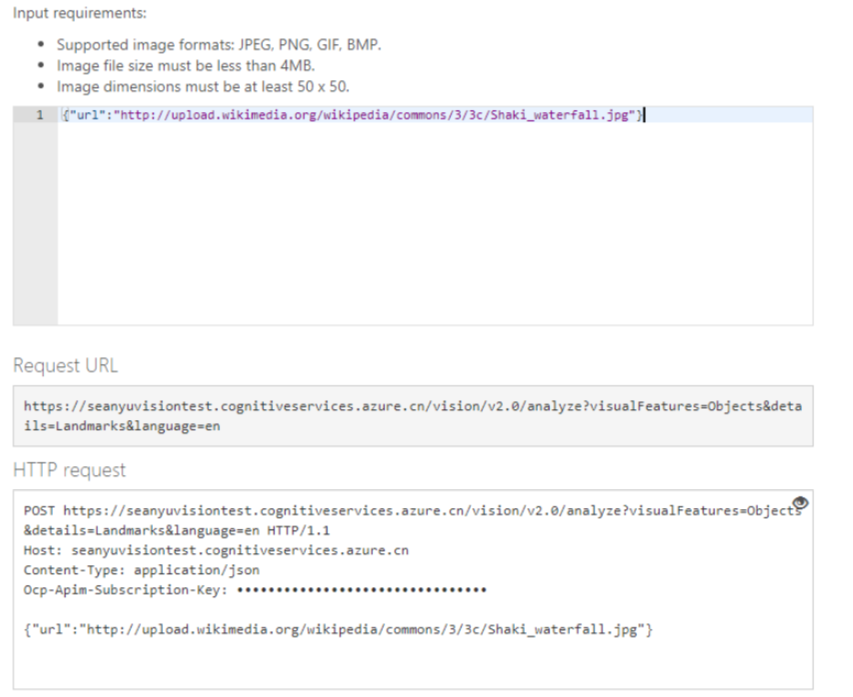
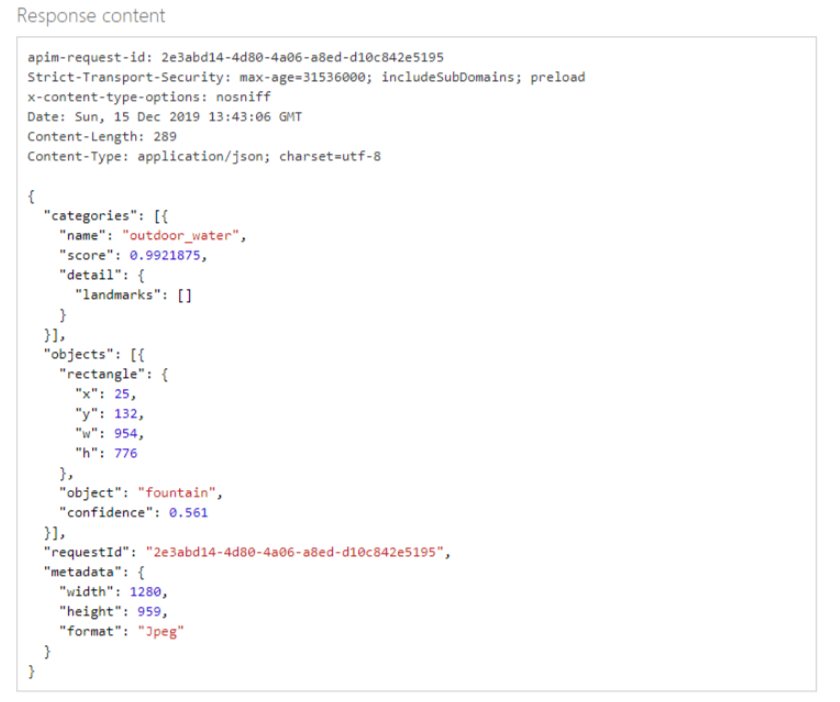
Request Body和结果如下:
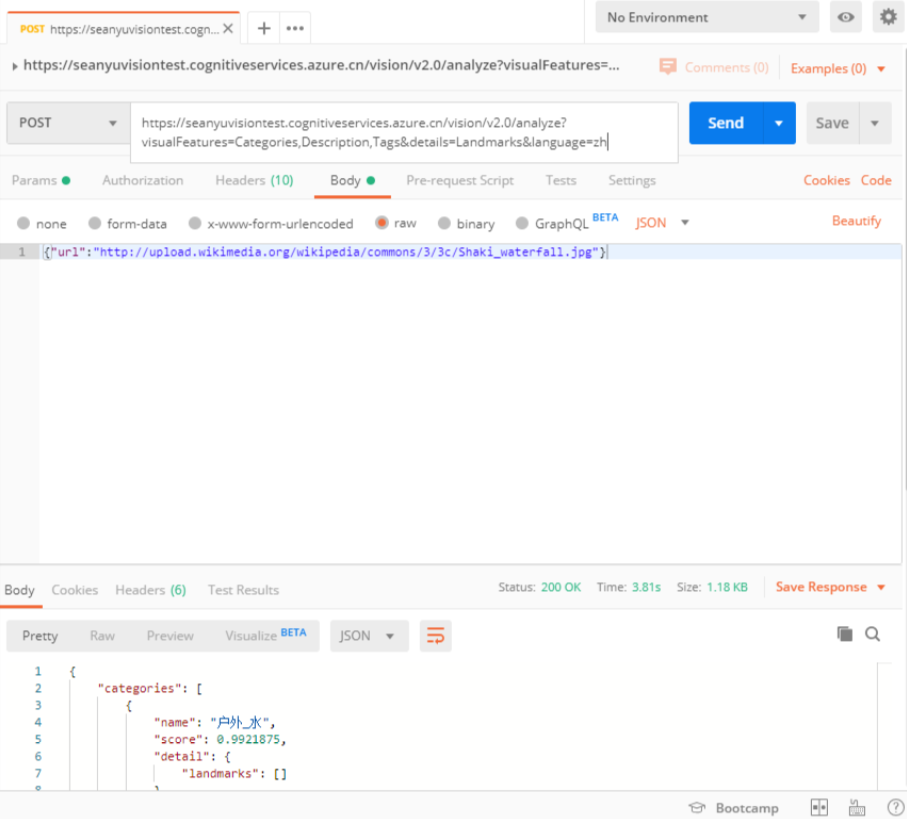
Postman测试如下图所示:


{kind=link}
你竟然讲起AI来了。。
哈哈,不是不是,讲越多越好,哈哈。