本文介绍:
通过Azure monitor监控虚拟机内存,并通过内存占用率触发某些操作。
主要原理:通过azure vm 扩展收集了 性能计数器的数据发送到log analytics workspace,在log analytics workspace中查询metrics的信息用来触发报警。
视频介绍:
图文介绍:
Azure vm 监控页面默认没有虚拟机的内存占用情况 ,因为虚拟机的cpu/硬盘/网络属于主机级别的监控,而内存属于os级别监控,需要额外的配置才能采集到。
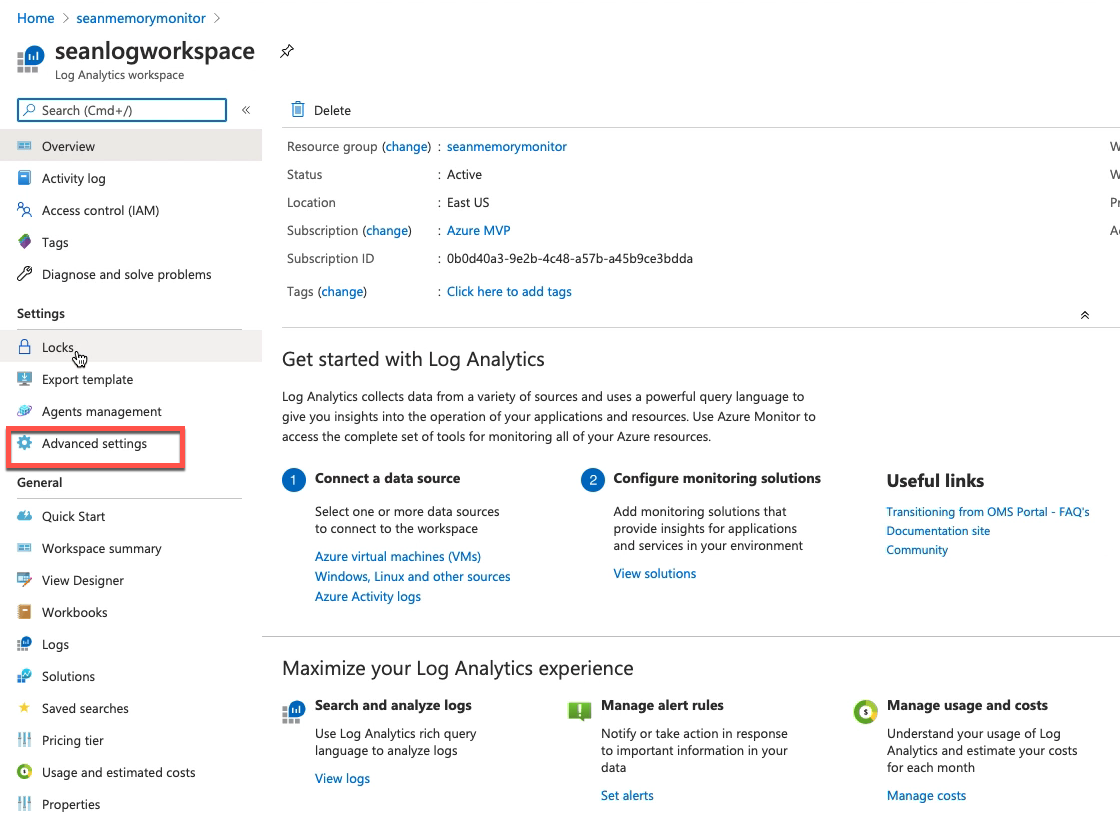
创建log analytics workspace:
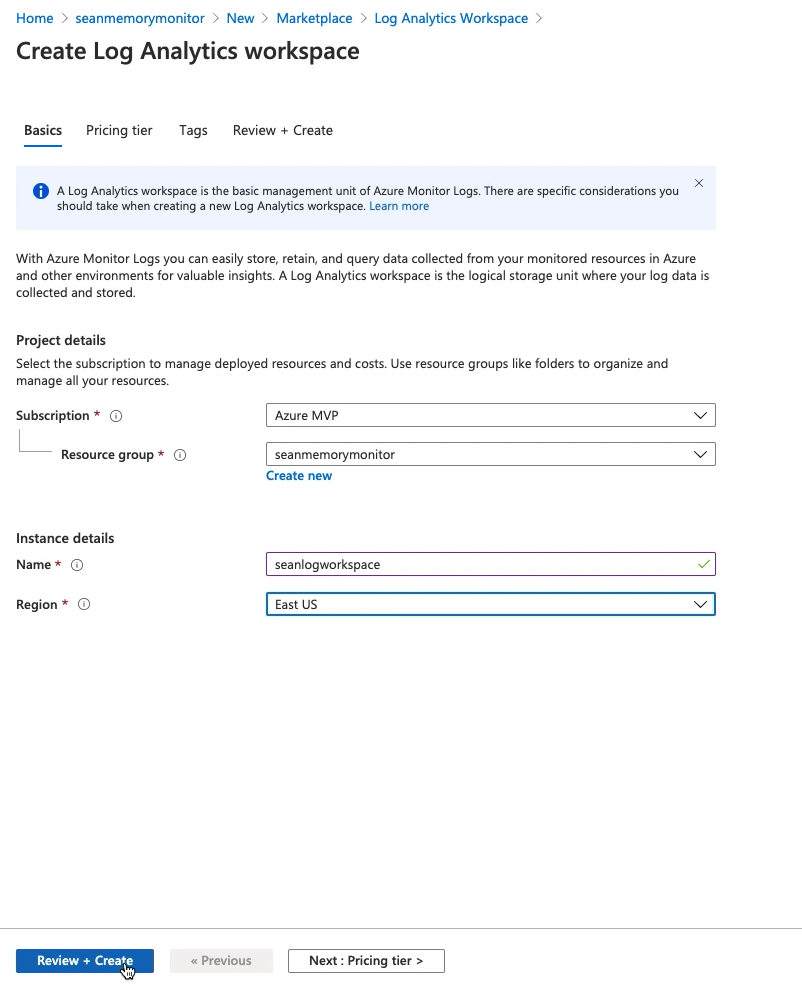
设定区域等配置后,创建:
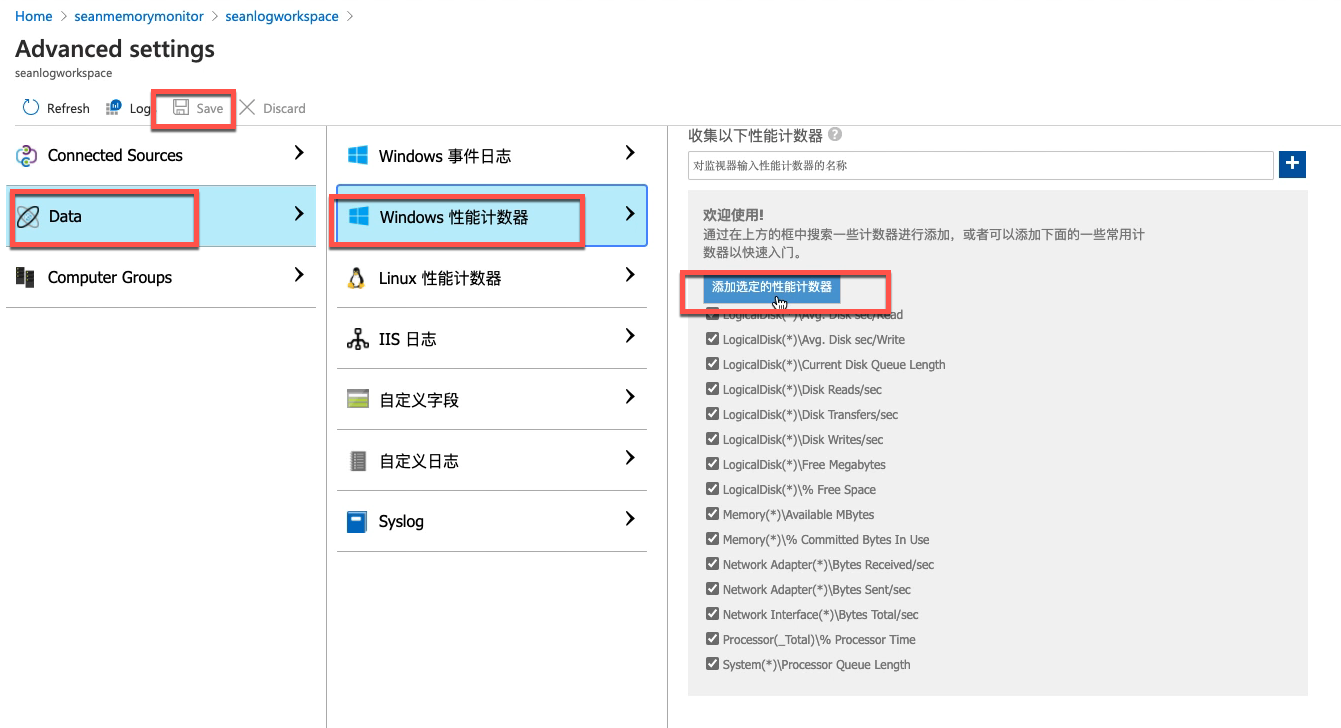
开启vm性能计数器:
针对windows 系统的采集:
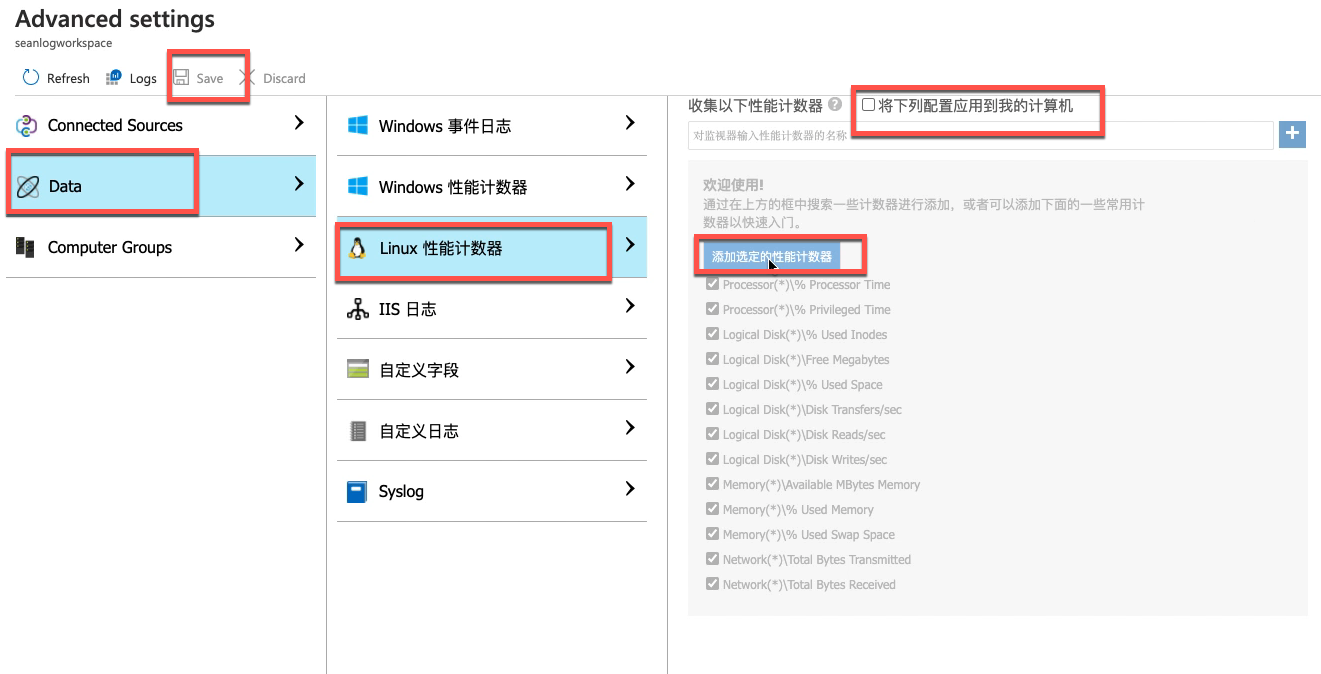
针对linux 系统:
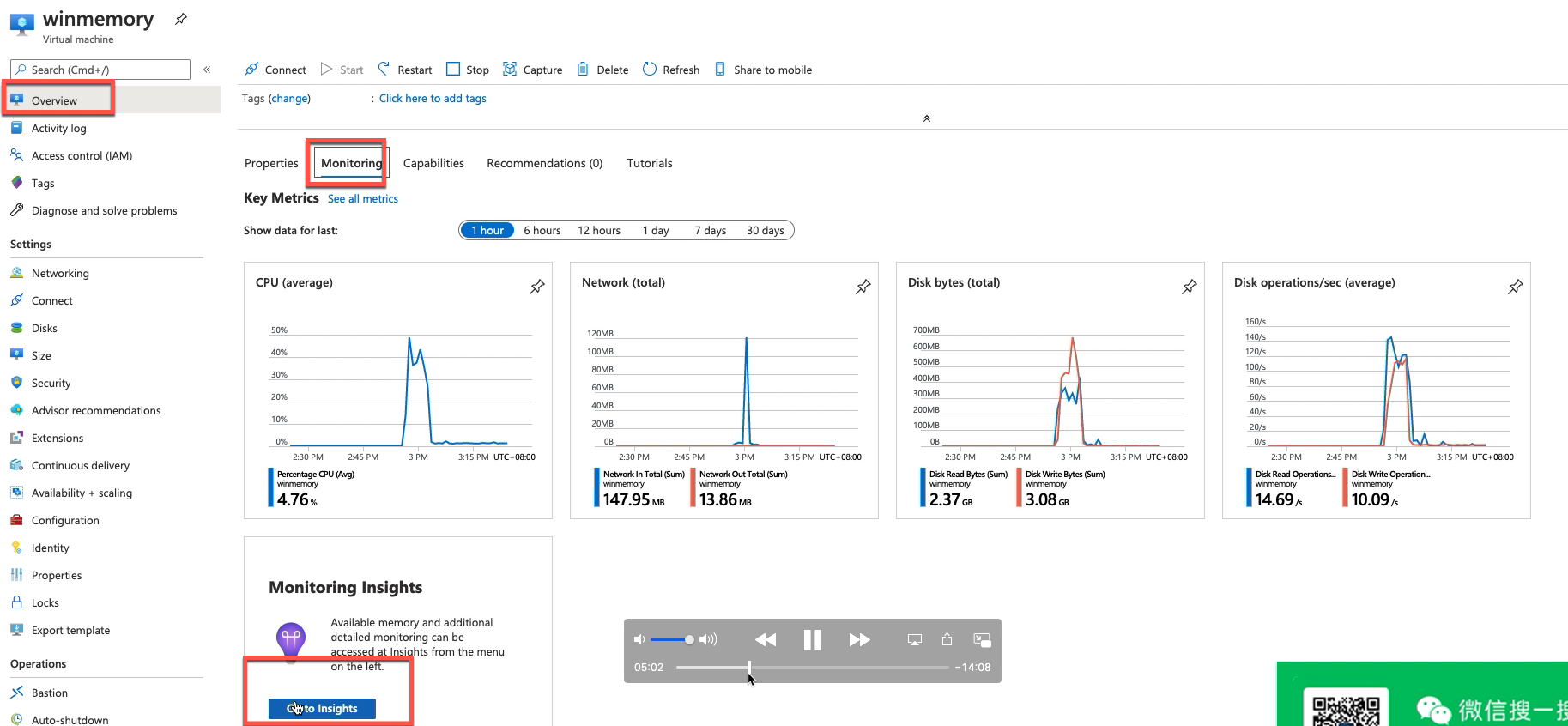
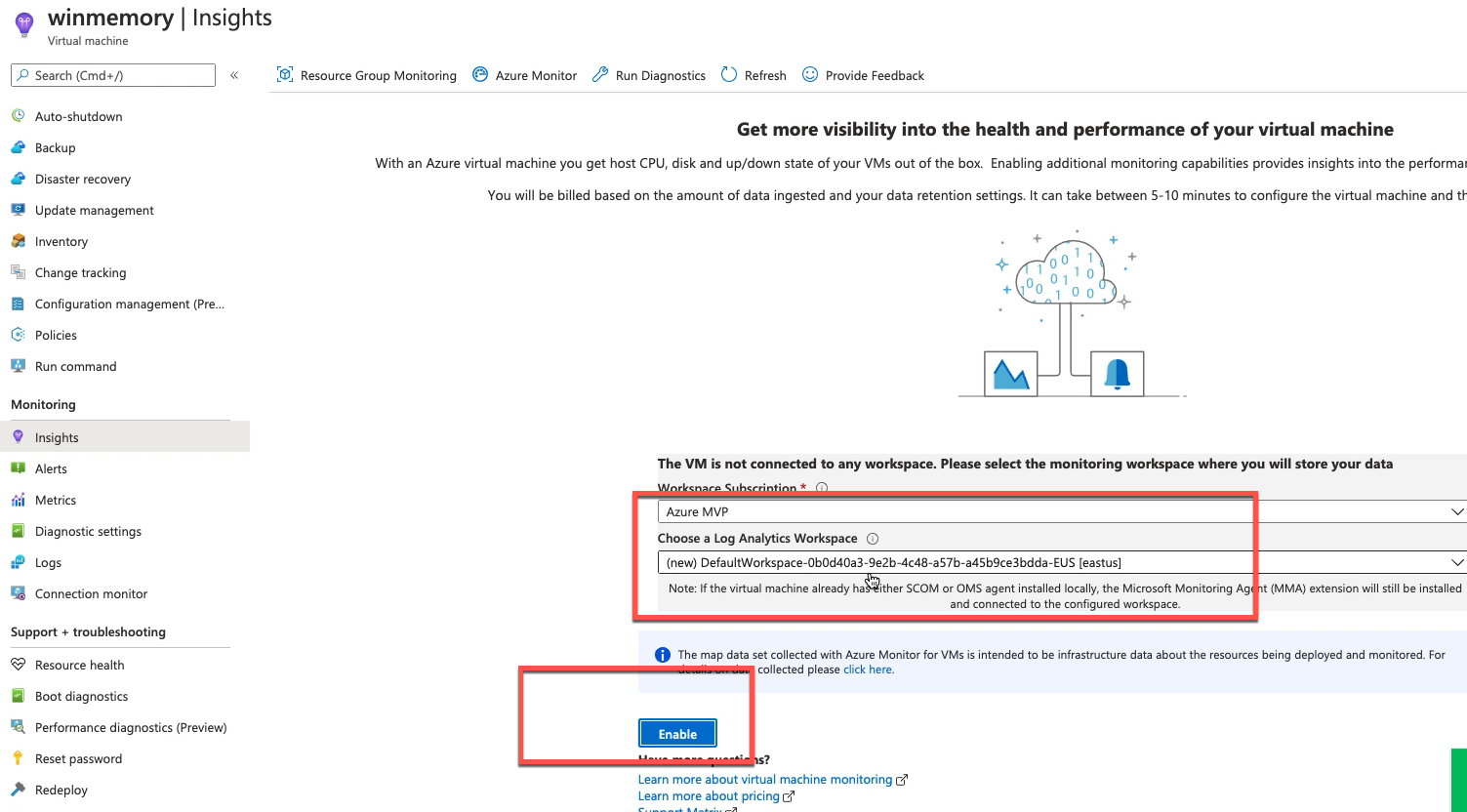
开启vm insights输出到log analytics workspace:
点击enable,等待验证通过
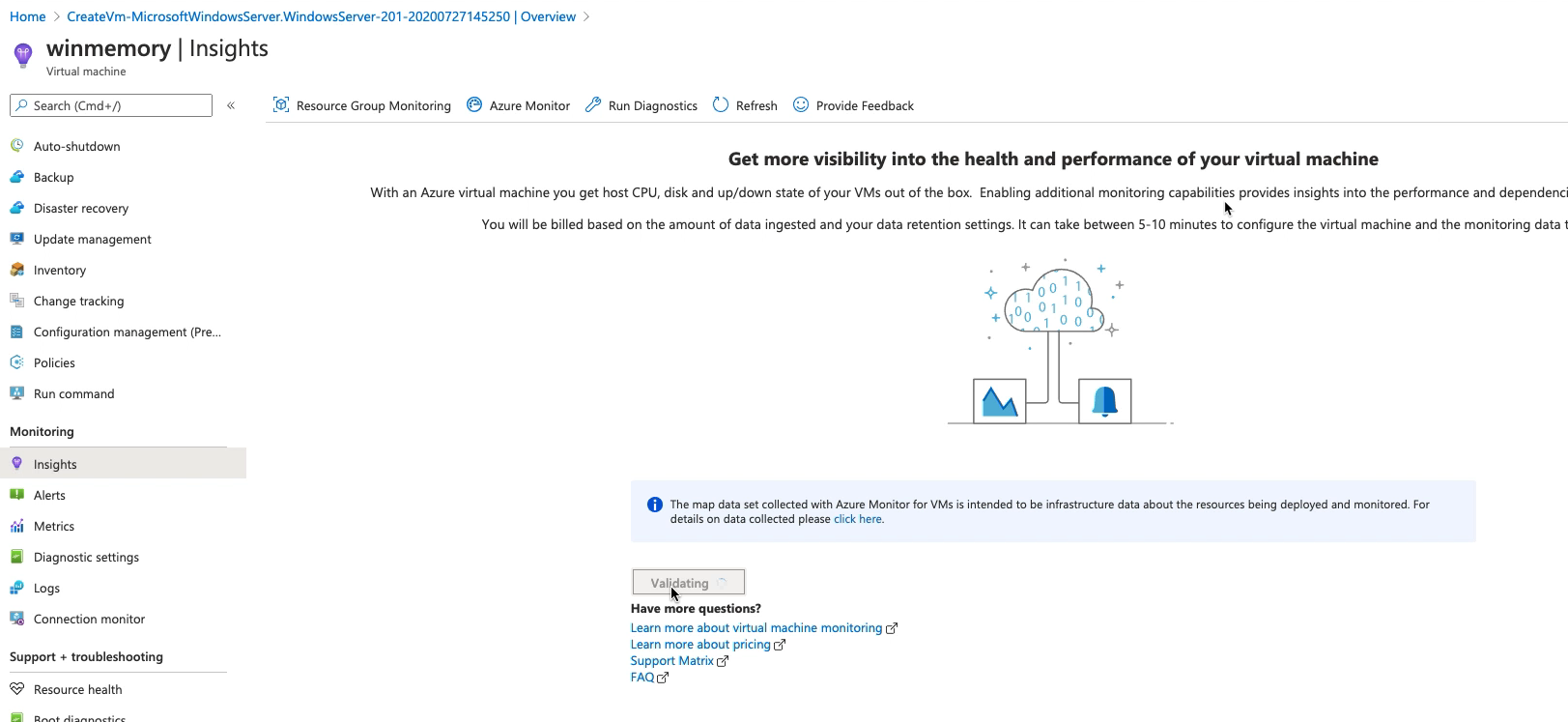
在下拉列表中选择刚才创建的log analytics workspace
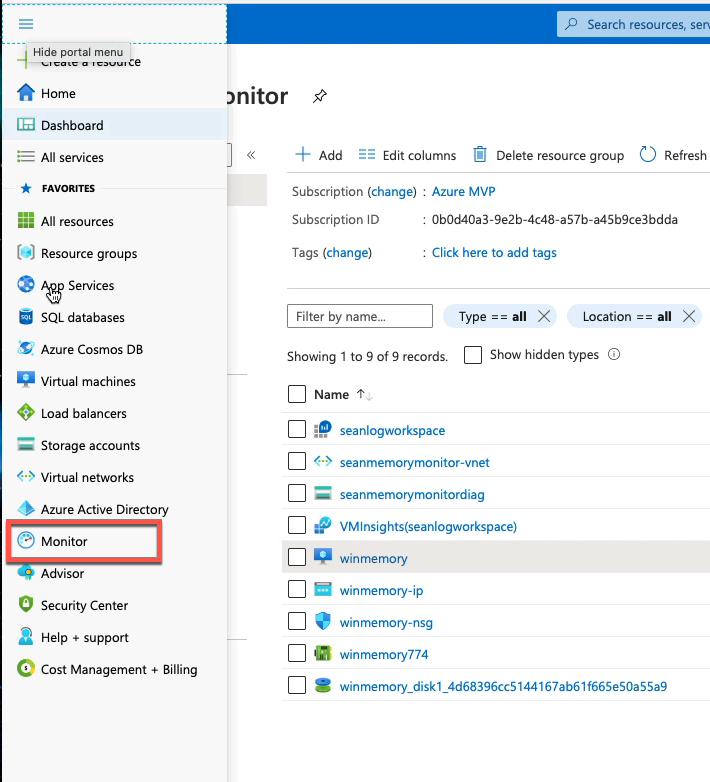
在azure monitor创建报警:
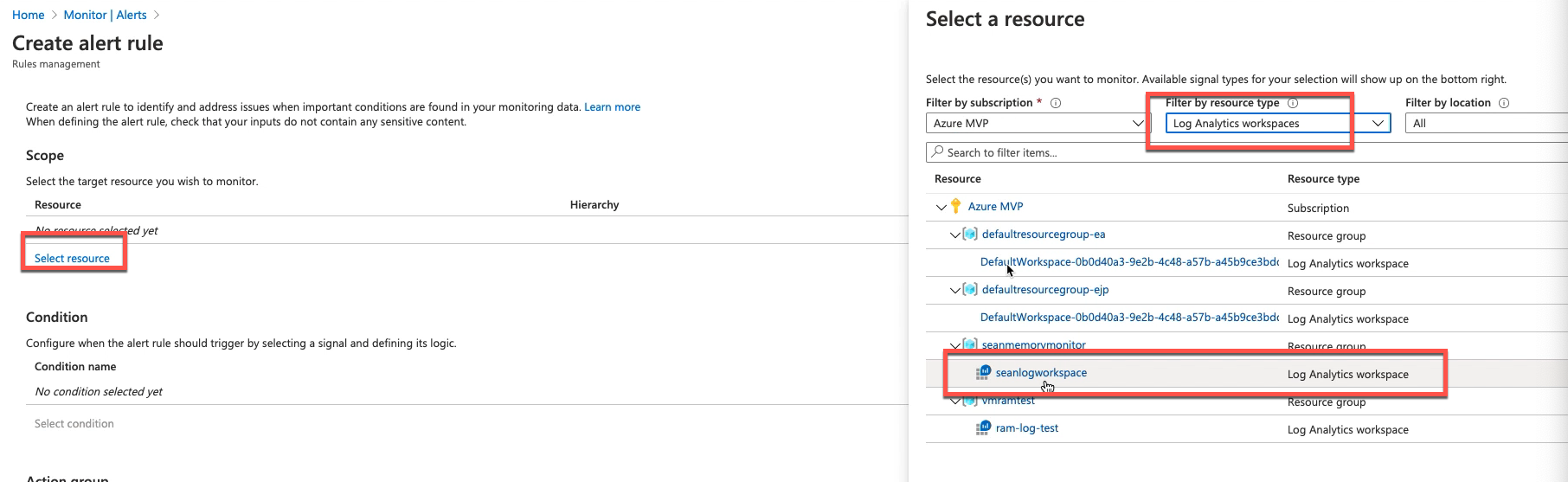
注意,报警需要在log analytics workspace 层级创建,不能是vm层级:
选择scope,此处应该为log analytics workspace,如果选择vm是无法正常工作的
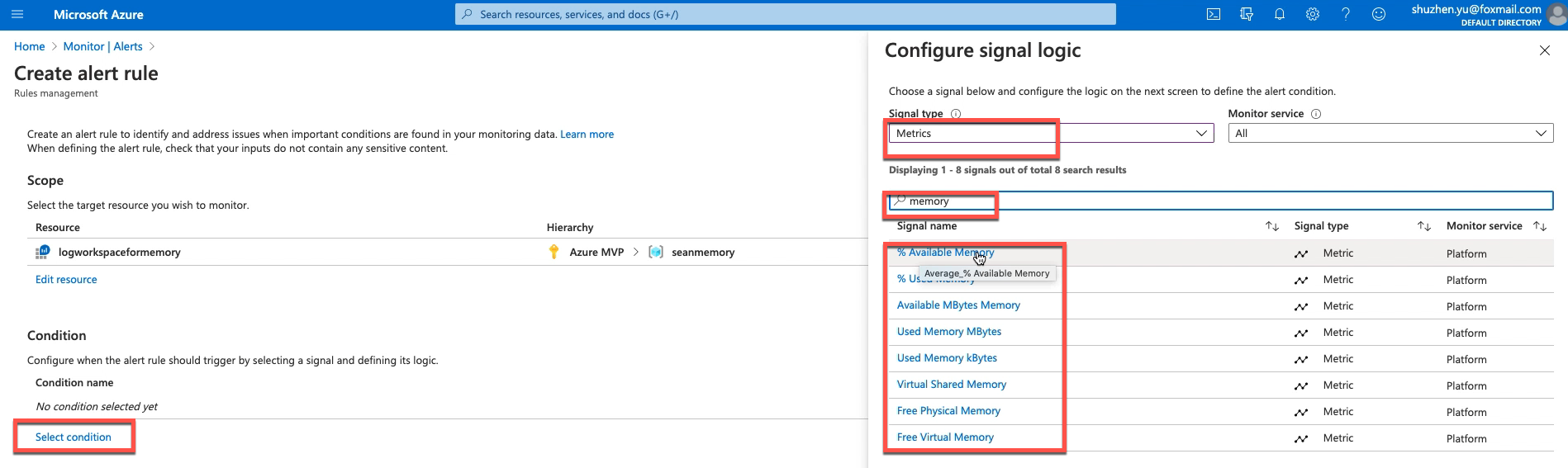
创建一个报警条件,本文中通过 metrics 从 操作系统性能计数器发送过来的数据里查询内存占用情况:
打开custom log search:
如果下图上方没有曲线,表示新配置的环境尚未收集到vm发送过来的数据,此初始化的过程经咨询azure 客服,最长可能有两个小时时延,经作者本文实测,8分钟左右才收到数据,但是一旦收到数据,收到的数据基本上就是分钟级别的时延了。
下方的 dimension 如果为默认为空,则表示不过滤任何实例,可以在此处设置具体要处理哪台vm的报警。
下图配置了linux系统的内存占用率:
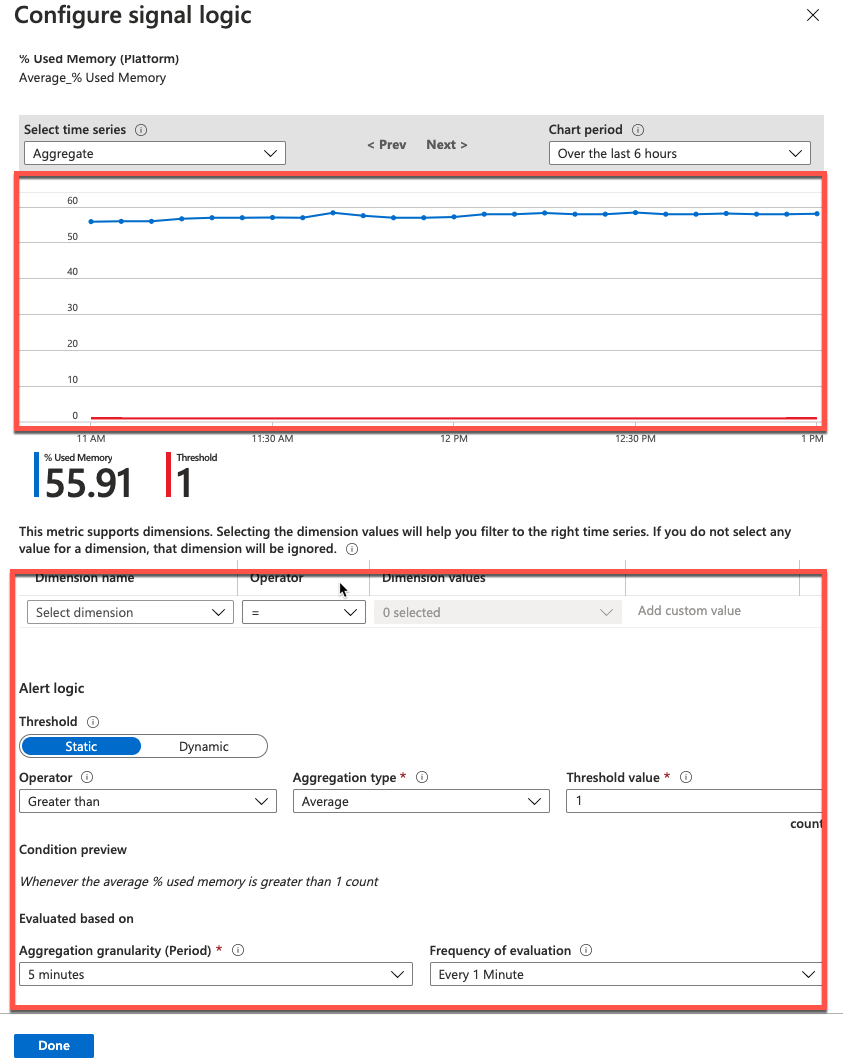
需要特别注意的是,此处的metrics在windows 系统和linux系统下的名称是不一样的,因此需针对windows 系统或者linux系统单独设置指标,
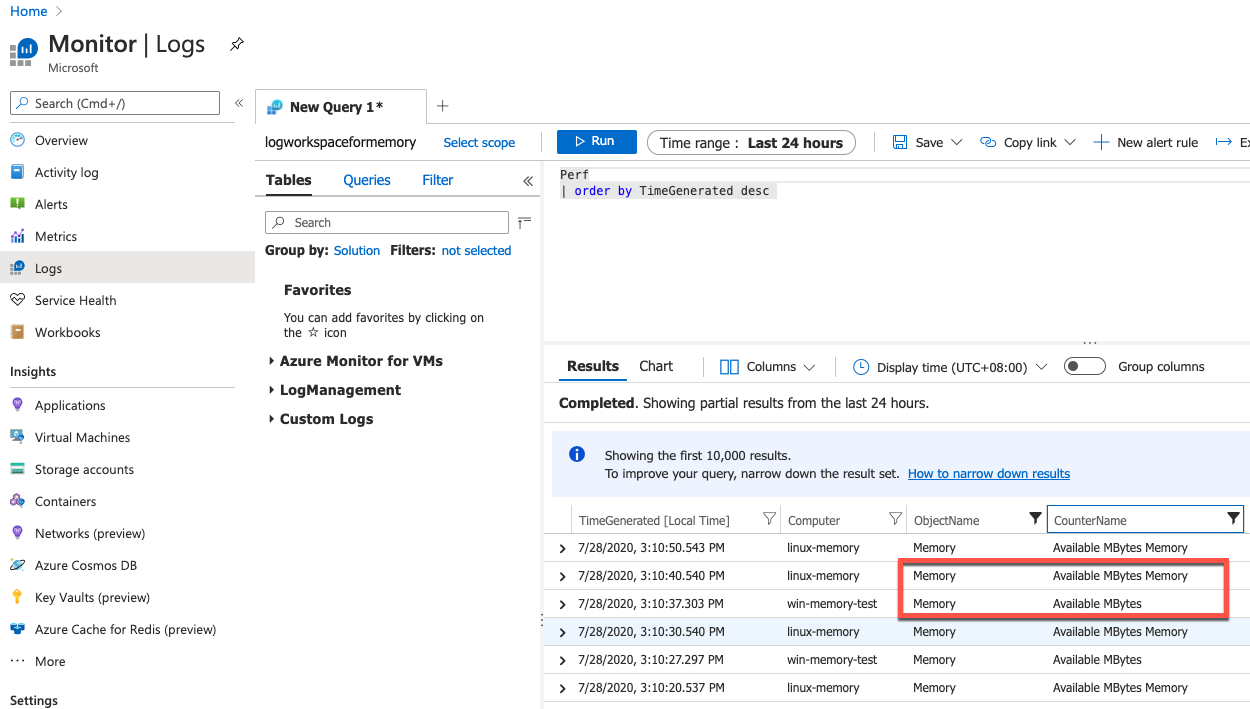
比如下图可用内存的名称在windows 和linux 里就不同。
具体的metrics可以在如下图所示界面中找到windows 和linux 系统的指标名称,然后根据这个名称在报警规则中配置metrics条件。
创建报警组,报警组是用来设置满足条件后如何报警的,通常报警组可以供多个报警条件使用的
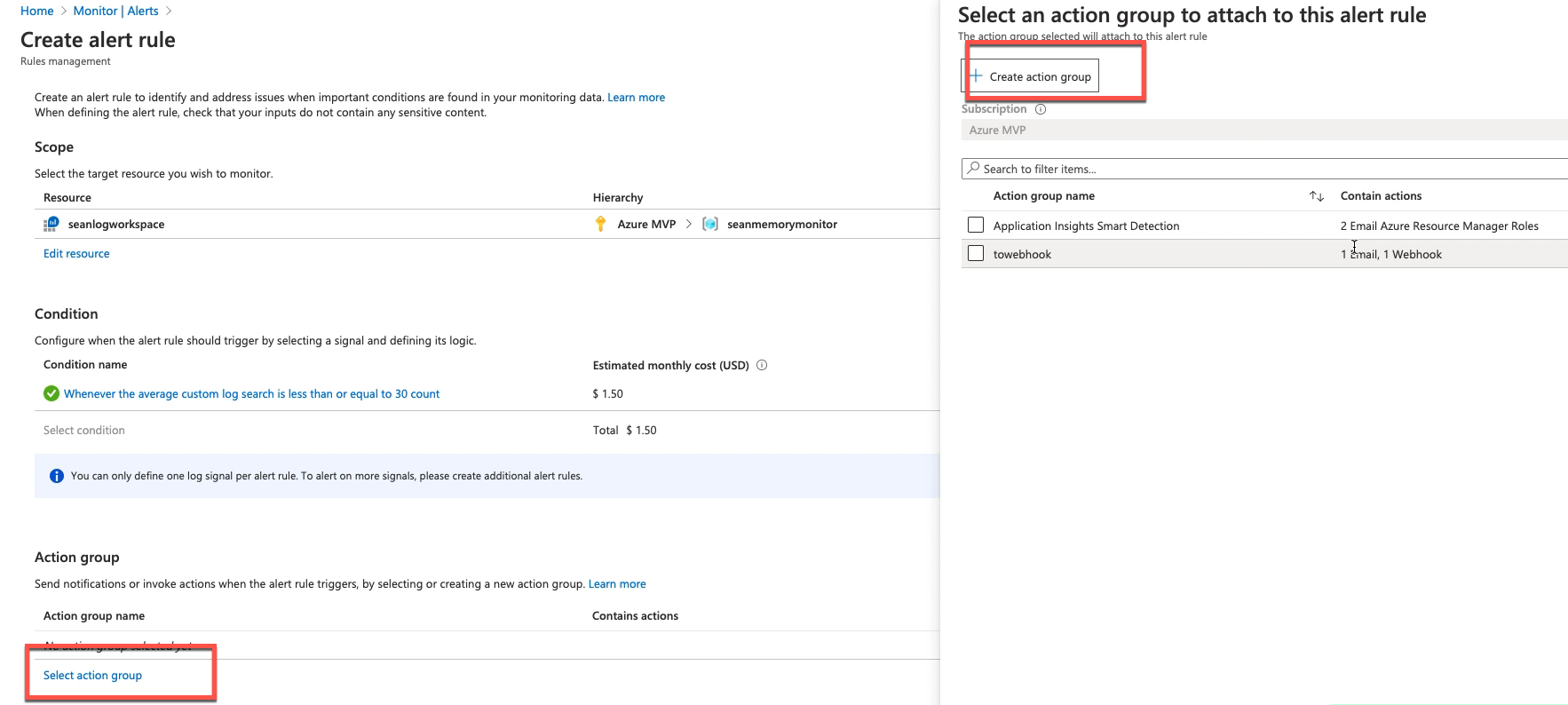
本例中增加了一个email

触发报警,观察结果:
进入vm中,可以使用第三方测试工具或者打开几个程序的方式使内存增加到报警阈值。
稍等一会可以收到报警邮件:
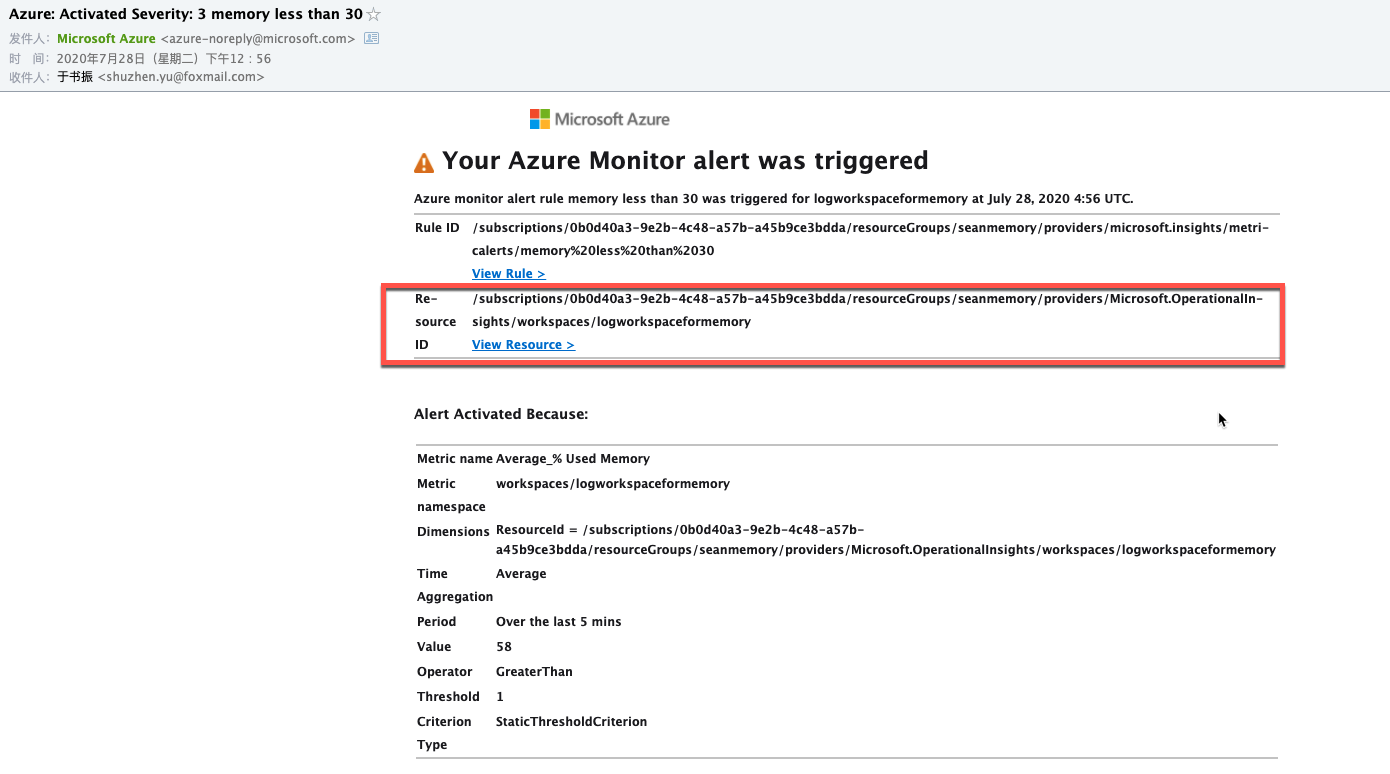
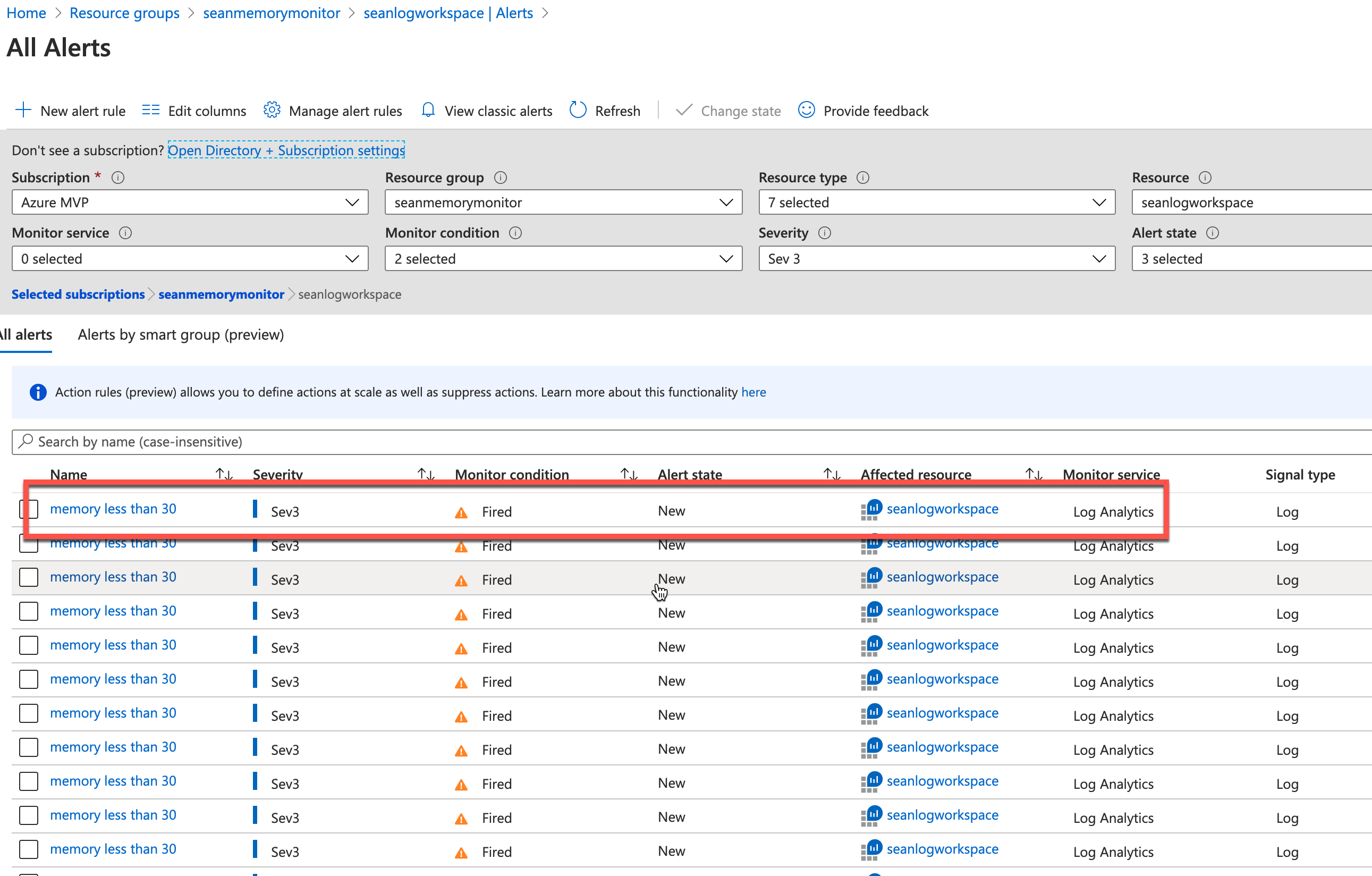
查阅报警记录,可根据报警严重程度进行过滤:
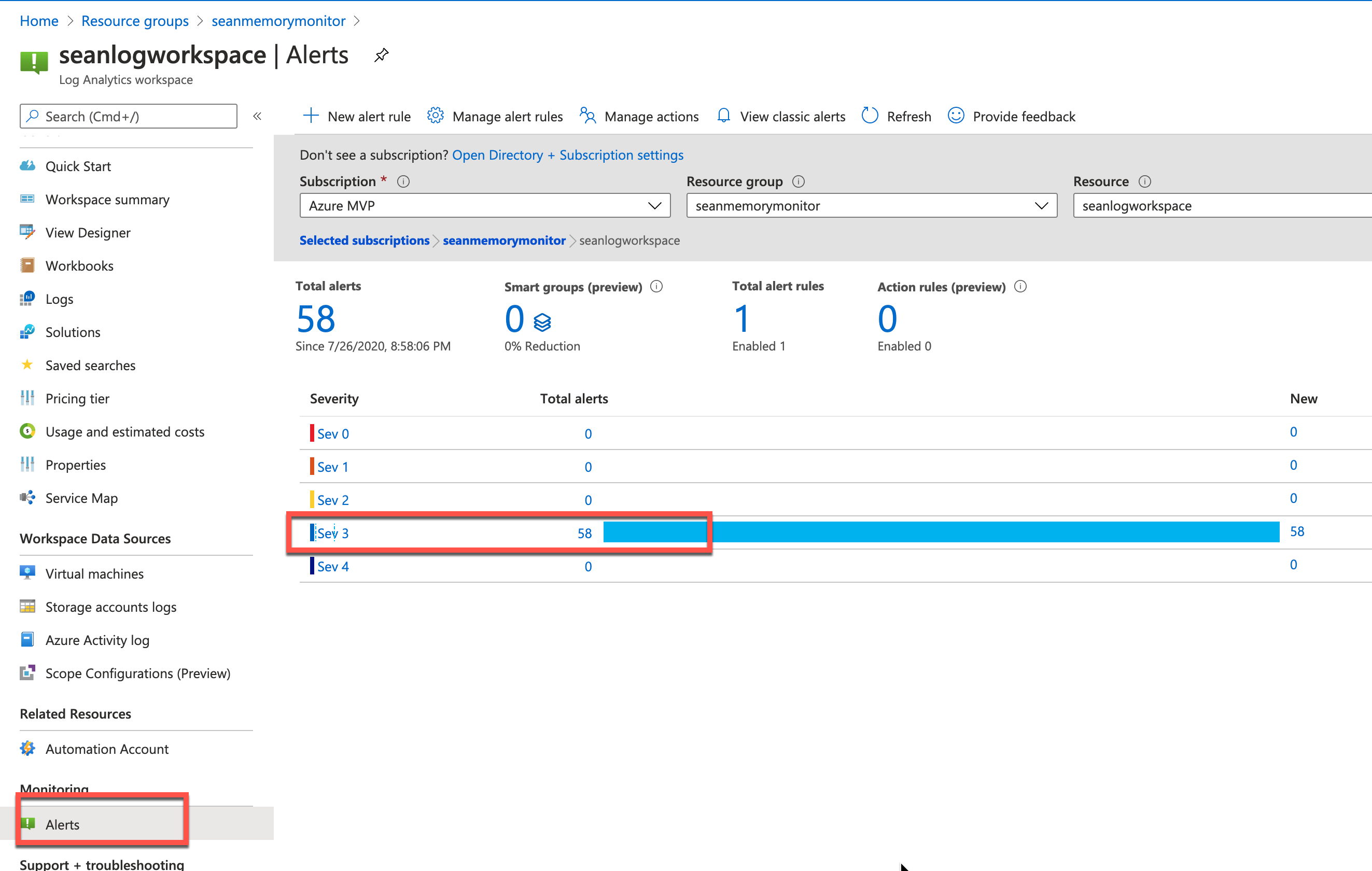
可查看内存报警记录: